
description.md 46 KB
IOT数据现状
1.静态非IOT数据接口
2.BDTP-数据服务(物理世界)与IOT数据如何关联?
BDTP-数据服务中的对象数据如下:
{
"id": "Eq32060500018c5dd28e0fb1470db61ed3de66a580c2",
"classCode": "WSDWPP",
"projectId": "Pj3206050001",
"grouping": 1,
"objType": "equipment",
"valid": 1,
"name": "生活给水水泵-VJEY2",
"localId": "Pump02",
"localName": "2号生活给水水泵",
"createTime": 1630928465000,
"createApp": "datacenter",
"updateTime": 1631066318000,
"updateApp": "datacenter",
"virtualInfoCodes": [],
"modeControl": "1",
"bimId": "Pj32060500017f8cd1a80eb411ec986e1f9988da50f8F6:1264008",
"bimLocation": "-107816.2,-61683.94,22758.0",
"runStatus": "2004-907",
"pipePressure": "2004-904",
"pumpTemperature": "2004-903",
"faultStatus": "2004-906"
}
其中下面四个信息点(对象属性)是动态信息点,其他信息点是静态信息点;
动态信息点,需要根据一个唯一标识去IOT服务获取数据,目前使用的唯一标识是表号-功能,同一个项目下,表号-功能号是唯一 的,所有动态信息点中保存的数据格式是表号-功能号。
"runStatus": "2004-907",
"pipePressure": "2004-904",
"pumpTemperature": "2004-903",
"faultStatus": "2004-906"
目前,物联网、工业互联网、车联网等智能互联技术在各个行业场景下快速普及应用,导致联网传感器、智能设备数量急剧增加,随之而来的海量时序监控数据存储、处理问题,也为时序数据库高效压缩、存储数据能力、查询分析提出了更高的要求。
时序数据(Time Series)
时序数据指数据元组根据时间戳(ti)升序排列的数据集合,可以被划分为:
1、单变量时序(Univariate Time Series,UTS):每次采集的数据元组集合为单个实数变量。
2、多变量时序(Multivariate Time Series ,MTS):每次采集的数据元组集合由多个实数序列组成,每个组成部分对映时序一个特征。
用数学范式表达时序可以被定义为:

示例:
| ... | time | data | ... |
|---|---|---|---|
| ... | 20001010 00:10:03 | 1005.00 | ... |
| ... | 20001010 00:10:21 | 1100.00 | ... |
| .. | 20001010 00:11:16 | 1192.00 | .. |
建筑IOT数据存储
| 项目id(projectId) | 表号(meter) | 功能号(funcid) | 采集时间(receiveTime) | 数据值(data) | 是否高频(gaopin) |
|---|---|---|---|---|---|
| 1101020001 | 67C8081 | 11101 | 20210601150948 | 23.9 | TRUE |
| 1101020001 | 67C8081 | 11201 | 20210601150948 | 26.6 | FALSE |
| 1101070037 | 1001 | 11 | 20010203040506 | 3.1 | FALSE |
3.分精度数据
什么是分精度?为啥需要分精度?分精度类型有啥
采集数据的都带有采集时间,查询采集的历史IOT数据,数据的时间间隔、数据密度不一致、采集值多,不适合业务直接使用,所以把历史数据按照一定的时间规则进行规整后的数据就是分精度数据;
分精度数据是系统中给定的规范时间步长的时序变量数据;
分精度类型,支持 1min、5min、15min、1h、1d
分精度数据向上兼容,比如最小分精度是5min,那么分精度一定也有15min、1h、1d的,没有1min的;
分精度数据的时间格式都是规整成的整数格式的,比如15min的,就回把时间格式化成每个小时的0min、15min、30min、45min四个分精度,如果采集数据缺失较多,就会有部分分精度不完整。
分精度定时轮询分精度配置规则进行计算,分精度可以重复计算,数据会自动覆盖;
3.1 时序数据分类
数据频率区分
(1)低频:采集频率比较低,几分钟一个数据,比如:有功电能、温湿度、CO2、CO等
(2)高频:采集频率比较高,几秒一个数据,比如:电流、电压、功率等
按照物理含义分类
(1)累积量 Accumulated quantity, abbr. Acc (Acc)
数值沿时间轴累计,连续性数值时变量。
例如:电耗,冷量,热量,水耗,燃气量,蒸汽量等,以及可以转化为此类特性的参数,如缴费剩余金额值等
(2)瞬时量 Instantaneous quantity, abbr. Inst (Inst)
数值沿时间轴连续变化的时变量,在物理意义上常表现为累积量的一阶导数。
例如:温度,压力,CO2浓度,电流,功率等
(3)状态量 Enumerate variable quantity, abbr. Enumv(Enumv)
延连续时间轴只有给定整数数值状态的时变量。
例如:冷却塔风机档位(0. 停,1. 低,2. 高),风机盘管风机档位(0. 停,1. 低,2. 中,3. 高)等
(4)通断变量 Boolean variable quantity, abbr. Boolv (Boolv)
延连续时间轴只有0/1两种数值状态的时变量。
例如:设备开关状态,系统报警状态,手自动状态等
(5)阶跃变量(Step)
(6)瞬时累计量(InAc)
(7)累计瞬时量(AcIn)
(8)文本类型
状态量的特殊情况,直接保存,不参与分精度计算
按照时间连续性分类
(1)连续变量 连续量,continuous quantity,abbr. Contu
数据对应固定的时间轴,即时间间隔固定,或相对固定。
例如:连续采集的数据,分精度数据。
(2)脉冲变量
脉冲量,pulse quantity,abbr. Pulse
随时间偶发性产生数据,时变量间的时间间隔没有规律,也不对应固定间隔的时间轴。
例如:报警消息,控制开指令,控制关指令等。
3.2 分精度数据库设定
分精度数据是系统中给定的规范时间步长的时序变量数据;
分精度数据库按照功能划分为操作数据库(OperationDB),修补数据库(AutorepairDB,ManurepairDB)和关联数据库(RelativeDB);
三类数据库之间的关系如下
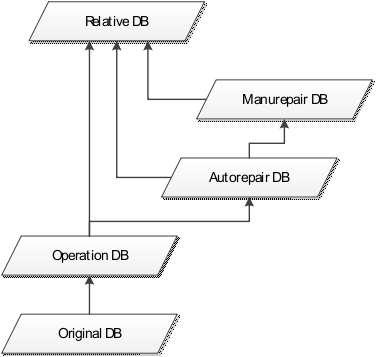
根据原始数据的采集周期,确定相对应操作数据库的分精度步长,即每个参数都对应一个采集属性CollectProperty = {(Contu,T ) / Pulse}.
系统暂时只处理低频采集数据,对于采集频率<1min的高频数据,系统不会长期保存原始数据,分精度数据按照低频数据的标准统一处理
采集周期无论长短,系统都会提供分精度处理。当采集周期较长时,系统提供的短周期分精度数据不能保障其有效性。即根据采集属性参数的情况,关联数据库中,有些库ProtectFlag = 1(1.不保障;0.保障)
下表标记说明:1)黑体加粗字,蓝色框,为操作数据库;2)其余均为相关数据库;3)橙色框,为不保障数据库。


3.3 计算说明
单库计算
Q. 系统如何获知每个采集数据应该对应操作库的哪种时间分精度?
A. 人工配置。通常是批量化的,配置难度不大。 需人工指定每个参数的采集属性CollectProperty = {(Contu, T ) / Pulse}. 即采集进来时是连续变量还是脉冲变量,若是连续变量,采集周期是多少。 采集属性会影响后续计算方法,主要区别在于脉冲式无“丢数”的概念,无法做数据诊断相关的系列计算。为此,限定累积量和瞬时量的采集属性都必须是连续型,哪怕采集周期设置较长。
Q. 系统如何获知每个采集数据应该对应操作库的哪种类型?
A. 根据参数的funcid自动匹配。funcid由项目实施方在采集器和调研文件中配置完成。
Q. 某些参数的物理意义决定其为整型变量,系统如何区分和处理?
A. 根据参数的funcid预定该参数是否为整型。 数据库中存储数据不区分整型和非整型;取整计算在使用侧定义,即当应用调用对象模型中的某整型参数,或调用某个整型的funcid参数时,在调用接口处做取整计算。
Q. 某些参数的物理意义决定其为整型变量,系统如何区分和处理?
A. 根据参数的funcid预定该参数是否为整型。
Q. 累积量插值结果是否会出现数值递减的情况?
A. 分精度插值计算采用P3 Hermite方法,即分段三阶Hermite插值法。这种插值方法具有保形性,即插值曲线的单调性与给定端点一致。
Q. 插值计算需要一定的样本段,在实时计算过程中,新的插值结果会不会跟之前的插值结果不同,从而导致计算结果不稳定?
A. 分段三阶Hermite插值法只保证一阶导数连续,不保证二阶导数连续,即计算结果对于一个采集周期以后的插值数据是稳定的。例如采集T = 1h,如下图
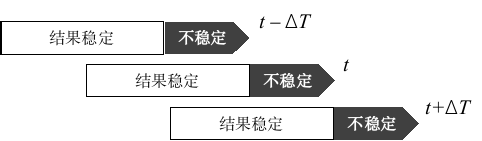 Hermite插值计算至少需要4个点,所以每次计算回溯历史的长度至少5T. 虽然最后一个T内的计算结果是不稳定的,但前面4T内的数据都是稳定的,不会对相关库计算造成重大影响。
Hermite插值计算至少需要4个点,所以每次计算回溯历史的长度至少5T. 虽然最后一个T内的计算结果是不稳定的,但前面4T内的数据都是稳定的,不会对相关库计算造成重大影响。
关联计算
Q. 关联数据库可以被人为操作么?
A. 不行。 每个数据的采集频度决定了操作数据库的时间分精度等级,对这个数据永远只能在这个精度等级上进行操作。 例如某参数X的操作分精度是15min,在逐日维度诊断出数据有误,需要修改数据,只能对15min数据列进行操作,进而得到逐日数据,不能直接修改1d数据列。 例如某参数X的操作分精度是15min,参数Y的操作分精度是1h,基于15min数据联合分析X与Y之后,需要修改Y数据,只能对1h数据列进行操作,进而得到15min数据,不能直接修改15min数据列。 这种问题在数据诊断和修补里会十分普遍。
Q. 修补数据库的精度如何确定?
A. 每个参数的修补数据库与该参数的操作数据库的时间精度一致。
Q. 这几个库之间的联动计算机制?
A. 1)实时联动计算,即一旦下级库发生计算,计算结束后就触发上级库计算。上下级关系如上图所示。 2)操作库、操作库的诊断标签和关联库是覆盖式计算;自动修补和人工修补库不覆盖,存储每一次的增量结果。 3)操作库只跟着原始库的变化发生计算,原始库有新数据,或发生改变,操作库进行对应时段的分精度计算。 4)诊断和自动修补计算有三种触发方式 i. 随时间实时计算。即当丢数时,操作库没有数据,但仍然在时间节点上打诊断标签,提供参考数据 ii. 操作库发生改变后,跟随计算。即数据再次恢复上传后,基于更新后的操作库,重新打诊断标签,重新提供参考数据 iii. 人为指定诊断和修补计算 5)操作库、自动修补库和人工修补库,任何一个库发生改变,关联库都要触发相应时段的更新计算。 6)关联库计算取用数据,以及应用取用操作精度的数据,取用原则是 i. 当操作数据诊断标记是正常时,直接使用操作库的数据; ii. 否则,使用最新的修补数据。 按照时间先后做优先选择,不按照人工或自动做优先选择。
3.4 分精度数据条件
3.4.1 数据采集条件
(1)采集器和采集软件所在服务器的网络通畅
(2)采集协议(UDP、TCP)统一
(3)采集端口能够接通
3.4.2 分精度数据计算条件
(1)原始数据original_month、original_day中有点位对应数据
(2)original_present中有>=计算时间的数据
(3)项目计算时间已经设定
(4)dy_pointlist中有参与计算的点位信息
3.4.3分精度数据(读数)
分精度数据(单值时序数据)
| 瞬时值 | Inst | 5min邻近值,15min邻近值,1h邻近值,1h平均值,1d平均值 |
| 累积值 | Acc | 15min累计值,1h累计值,1d累计值,15min差分值,1h差分值,1d差分值 |
| 布尔时序量 | Boolv | 变化脉冲,5min邻近值,15min邻近值,1h邻近值 |
| 单选枚举时序量 | Enumv | 变化脉冲,5min邻近值,15min邻近值,1h邻近值 |
(1)fjd_0_near:通过计算软件进行计算的分精度数据
(2)fjd_1_near:自动修复功能进行修复的分精度数据
(3)fjd_2_near:手动修复功能进行修复的分精度数据3、点位类型
3.5 数据的博锐业务分类
| 表分类 | 博锐业务说明 | HBase表名/分表举例 |
|---|---|---|
| 原始(读)数original_month | 由采集器发送给采集软件的采集数据 | original_month/original_month_yyyyMM |
| ①分精度数据fjd_0neartime | ①将在时间上分布不规则采集数据,通过一定算法计算,得出的时间精度规则均匀的原始数据 | fjd_0_near_15min、fjd_0_near_1h、fjd_0_near_1d |
| ②fjd_1neartime | ②对原始数①的数据通过一定算法进行修正过的数据 | fjd_1_near_15min、fjd_1_near_1h、fjd_1_near_1d |
| ③fjd_2neartime | ③对原始数①的数据进行人为的手动修正后的数据 | fjd_2_near_15min、fjd_2_near_1h、fjd_2_near_1d |
| fjdstatinsttime | 极值(最大值、最小值)、极值时间、采集次数、平均值、数据是否保障其有效性 | fjd_statinst_15min、fjd_statinst_1h、fjd_statinst_1d |
| 业务相关 | ||
| 能耗数据、仪表能耗dataservicedatatime | 由仪表的分精度数据通过做差得出来的仪表的差分能耗数据 | data_servicedata_15min、data_servicedata_1h、data_servicedata_1d |
| 计算单元能耗dataobjectdatatime | 由计算单元与仪表的数学关系,通过对多个仪表能耗数据进行运算得出 | data_objectdata_15min、data_objectdata_1h、data_objectdata_1d |
| 分项能耗dataenergydatatime | 由分项与仪表或者支路(支路与仪表具有关联)的关系公式,计算得出(公式有可能会乘以变比系数) | data_energydata_15min、data_energydata_1h、data_energydata_1d |
3.6、数据流转
| 流转方向 | 流转方向 | 流转方向 | 流转方向 | 流转方向 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 仪表 | ---> | ---> | original_present (最新采集数据) | |||||||
| 传感器 | ---> | --->采集器 | ---> | 采集软件 ---> | ---> | original_month(低频采集数据,按月分表) | ---> | 计算引擎 | ---> | | |
| 数据对接 | ---> | ---> | original_day(高频采集数据,按天分表) | | | ||||||
| | | ||||||||||
| 分项能耗 energydata | <--- | 支路、计算单元能耗objectdata | <--- | 仪表能耗 servicedata | <--- | 仪表读数 fjd_0 | <--- | | | ||
| | | | | | | | | |||||||
| energydata_max | objectdata_max | servicedata_max | | | |||||||
| | | | | |||||||||
| 租户能耗 tenantdata | <--- | 统一收费仪表能耗 servicedata | <--- | | | ||||||
| | | ||||||||||
| tenantdata_max |
4.iot服务有哪些服务,依赖关系是怎样的?

服务列表
| 服务名称 | 服务说明 | 说明 |
|---|---|---|
| iot-client | iot采集集成,负责集成各种IOT数据,对接各种二方、三方系统,各种协议的数据 | |
| iot-project | 边缘端IOT数据,上传下达的转发服务,所有iot数据都是传输到iot-project,然后再转发到iot-collect,只是上传下达的搬运工,不生产数据,也不处理数据。iot-project也可以提供边缘端的一些实时数据查询和websocket推送能力; | |
| iot-collect | 云端采集控制程序,这个服务是几个服务中唯一对业务方提供接口的服务,iot-collec提供主要接口:查询采集实时数据、查询分精度数据、采集值统计下发控制指令、查询指令结果,实时websocket推送数据等。 | |
| compute-engine | 分精度计算程序,根据数据库中配置的项目ID+表号+功能号+最小分精度类型,计算出对应的分精度;其实有两个程序。 | |
| iot-onlinestatus | 计算设备和系统的在离线状态;这是一个证明自己还或者的命题,正常理解中,在离线状态应该可以采集到,是一种IOT数据,但是实际情况下,在离线状态采集不到,大部分对象不会证明自己还活着,需要根据对象有没有其他的活动来推断;具体就是:如果对象在最近一段时间 有过其他的采集数据,那么设置设备在线,反之离线。 |
数据降频
如果数据采集频率很高,部分相对重复的数据应该降频处理,降频触发规则如下:
1.两个iot数据的采集时间很接近 60秒
2.两个iot数据的数据值差值的绝对值很小 小于0.09
3.两个iot数据的数据值比例值相差很小 小于1%
3个条件同时满足,那么认为采集数据重复,直接丢弃掉后受到的iot数据;
5.IOT数据存储
使用了什么数据库,什么中间件,存在哪些表里面?
所有物理世界的静态数据使用mysql存储
所有动态的IOT数据使用Hbase 存储,底层是byte数组;
操作Hbase使用中间件是zillion,zillion是公司自研的中间,提供Hbase的二级索引功能和常用数据格式支持,提供自定义的JSON格式的DDL,DML(库表的增删改查,数据记录的增删改查),自研配置zillion的Hbase界面化工具HbaseCat,类似于navicat操作mysql。
常用库表说明
| 库名 | 表名 | 表说明 | 分库分表(默认否) |
|---|---|---|---|
| db_public | original_present | iot实时数据表 | |
| db_public | original_month | iot历史数据 | 月份分表 |
| db_public | originalsetpresent | 控制指令实时值 | |
| db_public | originalset | 控制指令历史记录 | |
| db_public | fjd_0neartime | time分精度结果表 | 月份分表 |
| db_public | fjdstatinsttime | 极值(最大值、最小值)、极值时间、采集次数、平均值、数据是否保障其有效性 | 月份分表 |
| db_public | dy_pointlist | 分精度配置规则,配置所有需要计算分精度的 项目ID+表号+功能号+最小分精度类型 | |
| db_public | fjd_0_buildingcomputetime | 配置要计算分精度的项目和开始下次计算分精度的时间,每次计算分精度后自动更新该时间 | |
| db_public | fjd_0_computedetail | 分精度计算详情 | |
| db_public | fjd_0_metercomputetime | 分精度计算时间表,记录所有表号-功能号下次计算分精度的时间 | |
| db_public | original_happening | 记录所有文本类型的数据,不带表号功能号 | |
| db_public | original_textpresent | 带表号-功能号的文本数据,实时数据表 | |
| db_public | original_text | 带表号-功能号的文本数据,历史数据表 | 月份分表 |
6.IOT服务待改进点
1.服务有状态,无法做集群部署
有状态体现在两点: 1.实时数据本地内存缓存、 2.云边通讯TCP、UDP,集群有通讯问题
iot服务iot-collect对外提供接口:采集实时数据、分精度数据、采集值统计、控制指令、查询指令结果。
提供的核心接口就是实时数据、分精度数据,分精度数据数据量,每次从数据库查询。实时数据查询具有批量和高并发的特点,所以实时数据有内存缓存,并且每次有IOT数据后实时更新缓存,查询的时候不查库只查内存。
2.服务性能、稳定性、功能
稳定性:
香港置地的iot-collect服务 偶尔发生阻塞后无法提供服务,分精度不计算(2次);
云端服务重启后几率性无法自动重连问题
性能:
功能:
mqtt支持、
直接接受http格式iot数据等
在线状态信息点判断机制。
3.服务架构
服务通过(Mina、Netty)TCP/UDP的数据传输,IOT数据不重不漏,自动补发。数据失败后的自动补发机制目前依赖iot-client。
zillion的维护和新功能、扩展性;(对比开源Phoenix)
招商集团的安全要求,不能TCP直连;
时序数据库的考虑
分精度人为配置易忘易漏易错易不一致、没有和数据字典打通,不支持数据反查。
4.报文格式、数据类型、代码注释
数据的报文格式较多,考虑优化精简
整数和小数无法区分
回包机制(回包根据表号和功能号查找判断,可报文格式增加报文来源地址)
5、...
7.IBMS控制流程说明:
7.1、涉及服务:
zkt-control:远端控制服务,负责日程、模式、日历和定时控制指令的生成
zkt-project-control:边缘端控制服务,接受zkt-project-control的定时轮询下发的指令,并在指令设置的时间下发指令到iot-project;
iot-project:边缘iot服务,http方式接受控制指令,并转发指令到iot-client服务,同时下发记录同步到iot-collect
iot-collect:云端采集控制服务,http方式接受控制指令,也接受iot-project控制记录保存到hbase;
iot-client:对接设备或者子系统进行具体的采集和控制
7.2、服务版本:
服务最新版本:https://thoughts.teambition.com/workspaces/5f7001fdd8b0840016e073e7/docs/5fe1e4d4373983000167203c
7.3、涉及的表
| 库名 | 表名 | 表说明 | 服务 | 数据库类型 |
|---|---|---|---|---|
| db_public | originalsetpresent | 控制指令实时值 | iot-collect | hbase |
| db_public | originalset | 控制指令历史记录 | iot-collect | hbase |
| control-center | command_resul | 下发指令会记录 | zkt-control | mysql |
7.4、接口
接口文档:http://39.102.54.110:9009/iot/iot.html#%E5%90%8C%E6%AD%A5%E6%8E%A7%E5%88%B6
iot-project(iot-collect)手动控制接口:
http://ip:port/sync_pointset_post
{
"data": "1.0",
"meter": "6666666",
"funcid": 903,
"building": "5001120003"
}
7.5、控制流程
1.新建模式、日程、绑定设备、日历绑定模式(详见产品文档,产品使用说明等)
2.到达设置时间点后观察hbase数据库记录,如果有记录,说明没问题,没记录的时候:检查设备的绑点、
手自动状态设定、日程日历设定、数据库记录和相关服务日志;
3.自动控制前先保证手动控制是可以控制成功,手动控制后记得修改回去对应的手自动状态;
4.云-》边的指令默认15分钟下发一次,每次下发的时候下发15分钟后的2小时的指令,极限时间是15+15=30分钟,所以新建日程中30分钟后的指令才是一定可以下发,15分钟内的一定不会下发下去的;
相关时间的可选默认配置如下:
#每次下发2个小时的定时控制时令
command.add.hour=2
#每次下发的时候下发15分钟之后的指令
command.start.minute:15
#15分钟下发一次指令
command.cycle.minute=15
8.iot数据质量需求修改
1.http接口查询实时iot数据数据,超过时间阈值没有实时数据的返回结果中iot数据信息字段不存在或者为null;
返回示例:
{
"building": "1101070037",
"points": [
{
"virtual": false,
"building": "1101070037",
"operation": null,
"meter": "1001",
"funcid": 10101,
"data": null,
"receivetime": null,
"status": null,
"endtime": null
}
],
"receivetime": "20201224192034",
"status": "finish:success"
}
或者:
{
"building": "1101070037",
"points": [
{
"virtual": false,
"building": "1101070037",
"meter": "1001",
"funcid": 10101,
}
],
"receivetime": "20201224192034",
"status": "finish:success"
}
2.websocket推送实时数据的,数据返回空字符串;
示例 有数据:{"data":"20220211100937;107911;903;0.0","type":"iot"} 无数据:{"data":"20220211100937;107911;903;","type":"iot"}
3.Hbase数据库中保存的原始数据不保存掉线为空(null)的数据,基于3点考虑:一个是为了排查问题方便,知道最近一次有效数据的时间,一个是兼容之前部分能源业务直连Hbase数据库的场景,一个是不影响分进度计算逻辑
4.数据质量的判断依赖于两点:
iot-client上报信息点为数值类型且信息点包含有效期,如果iot-client没有升级或者没有上报,那么认为所有数据都是有效的,有效判读去上报时间,与iot数据时间无关;iot链路上有iot-project服务; (集团业务如果使用的iot-client-->iot-collect的链路,不会进行发数据质量的判断,iot数据质量判断在边缘项目iot-project中判断,也就是只有 iot-client-->iot-projecr-->iot-collect的链路做数据质量的逻辑 iot-project如果接受多个项目的数据的情况,数据质量判断值判断只判断配置文件中配置的单个项目,避免多项目数据质量判断的压力和时效性问题)
5.服务重启说明
当前版本的服务重启后会自动加载Hbase最新的数据放入缓存,但是为了保证数据指令有效,未来版本中:
a. iot-project重启,需要iot-client发送全部最新数据;
iot-client-->iot-project-->iot-collect iot-client与iot-project的心跳丢失后iot-client负责上传的数据需要内存中对应的数据写null,hbase中不做数据更新。iot-collect重启,iot-project中需要推送全量数据到iot-collect;
6.分精度数据保持原逻辑不变,离线及其不可靠的空数据不会计入分精度计算;
7.控制业务之前依赖的是控制心跳,此次升级以后增加了新的信息点和有效期上传报文机制,采集和控制的信息点及其判断统统以最新点位心跳机制,原有的控制心跳作废; iot-control云端控制服务作废,iot-collect同时负责采集和控制; 下发控制的时候,如果数据的值为null,控制下发的报文应该反馈离线不能控制,保证逻辑和之前一致。
8.本地升级不会考虑提议中重复数据多次上报的问题,即使数据不变的iot数据也要定时不断上报;
9.采集数据不经过iot-cilent直达iot-project/iot-collect的数据,不会进行点位清单及其有效期上传,所以最新数据长期有效
10 有效期约束
为了高效及时的判断海量设备离线,可以基于定时任务,轮训,redis的zset,DelayQueue延迟队列,MQ等,但是效率和资源占用都不够友好, 计划使用时间轮算法判断,需要设置几个固定的时间轮进行判断: 分精度类型,支持 1min、5min、15min、1h、1d,有效期的时间轮设置为分精度的2倍(2min、10min、30min、2h、2d) 比如设备上报频率是1分钟1次,有效期设置为2min,2分钟多几秒就会收到数据就会收到设备离线的iot数据 数据有效期至少是上报周期的2倍以上
11 为了兼容可能出现的同一个点位的采集和控制不是一个客户端的情况,约定如下:因为采集控制使用同一个信息点心跳,采集的哪个客户都最后发的包就回包给谁,控制的优先认心跳,哪个客户端最近发过点位有效期的心跳,就优先控制到哪个客户端,并且一个命令一会控制一次;
12 报文格式参考报文格式文档
13 数据质量判断时候处理好有效期和数据降频的冲突问题,不能因为降频产生不必要的离线数据;
部分疑问说明:
1.心跳间隔超过多长时间后认为丢失心跳,需要重新连接?
服务之间会长期保持连接,如果连接断开了,下次发数据的时候就会自动重新连接,重新建立连接的时候客户侧会向服务侧推一次送全量数据; TCP断开连接那么久认为心跳丢失;服务重新连接是客户端行为,服务侧不做约束;
2.有效期支持自定义
为了实现的高效性和简洁,暂时不支持自定义有效期,只支持分精度类型x2的固定几个有效期,具体参考报文格式文档;如果明确目前不能满足需求,及时沟通调整;
3.文档完善
服务接口文档,通讯协议,服务说明文档,服务部署文档已经详细提供; 具体细节对接判断流程图等,考虑到投入产出,暂时不做更详细书写,有具体疑问问题的会及时解答并根据情况更新文档;
4.关于数据质量判断带来的性能压力说明,如果都用2分钟有效期的话,压力有多大?
实时的数据质量判断在云端会有可预见的压力,所以目前实现的数据质量实现强依赖于边缘侧iot-project服务,数据质量的判断和产生都在iot-project服务中产生; 所有数据有效期都是2分钟,那么数据上传的频率都要小于等于1分钟,较大的iot数据的压力主要在Hbase侧,尤其是分精度的计算压力,服务本身压力可以处理;
最新问题讨论
问题1:信息点有效期第一次约定中是说明有效期内没有收到新的报文生成离线判断,但是服务离线的情况下还继续等到有效期才生成离线数据不合理;
可以使用服务侧心跳判定(实现复杂一些,判断要等到心跳结束,判断不及时,需要额外线程监听心跳) 可以使用TCP连接断开判定(判断实时,实现简单,UDP不支持判断)
初步考虑使用TCP连接实时判断+有效期结束保底判断相结合,UDP的只依赖有效期判断
附录1:部分文档地址
附录2:能耗常用表结构
原始数记录表(按月)original_month
| 字段名 | 类型 | 说明 |
| building | String | 建筑唯一标识 |
| data | Double | 读数 |
| funcid | Long | 功能号 |
| meter | String | 表号 |
| receivetime | String | 接收 |
原始数记录表(按天)original_day
| 字段名 | 类型 | 说明 |
| building | String | 建筑唯一标识 |
| data | Double | 读数 |
| funcid | Long | 功能号 |
| meter | String | 表号 |
| receivetime | String | 接收 |
原始数最新接收数据表original_present
| 字段名 | 类型 | 说明 |
| building | String | 建筑唯一标识 |
| data | Double | 读数 |
| funcid | Long | 功能号 |
| meter | String | 表号 |
| receivetime | String | 接收时间 |
点位计算信息表(仪表清单)dy_pointlist
| 字段名 | 类型 | 说明 |
| building | String | 建筑唯一标识 |
| meter | String | 表号 |
| funcid | Long | 功能号 |
| data_type | String | 数据类型(Acc 累积量,Inst 瞬时量...) |
| collect_cycle | String | 分精度计算的最小时间粒度 |
项目计算时间信息表fjd_0_buildingcomputetime
| 字段名 | 类型 | 说明 |
| building | String | 建筑唯一标识 |
| compute_time | String | 计算到的时间 |
| first_compute_time | String | 首次计算时间 |
仪表计算的记录信息表fjd_0_metercomputetime
| 字段名 | 类型 | 说明 |
| building | String | 建筑唯一标识 |
| meter | String | 表号 |
| funcid | Long | 功能号 |
| first_compute_time | String | 首次计算时间 |
| next_data_time | String |
分精度数据记录表fjd_0neartime
| 字段名 | 类型 | 说明 |
| building | String | 建筑唯一标识 |
| meter | String | 表号 |
| funcid | Long | 功能号 |
| data_time | String | 时间 |
| data_flag | Long | 数据可靠标签0 可靠 |
| data_value | Double | 数值 |
分精度数据计算日志表fjd_0_computelog
| 字段名 | 类型 | 说明 |
| building | String | 建筑唯一标识 |
| compute_round | Long | 计算轮次 |
| fjd_compute_time_from | String | fjd数据开始时间 |
| fjd_compute_time_to | String | fjd数据结束时间 |
| is_finished | Long | 是否计算完成1 完成0 未完成 |
| compute_time_from | String | 计算开始时间 |
| compute_time_to | String | 计算结束时间 |
分精度数据计算详细日志表fjd_0_computedetail
| 字段名 | 类型 | 说明 |
| building | String | 建筑唯一标识 |
| compute_round | Long | 计算轮次 |
| funcid | Long | 功能号 |
| meter | String | 仪表id |
| operate_time_to | String | 计算操作时间 |
| valid_time_from | String | fjd数据开始时间 |
| valid_time_to | String | fjd数据结束时间 |
仪表能耗表dataservicedatatime
| 字段名 | 类型 | 说明 |
| building | String | 建筑唯一标识 |
| meter | String | 仪表ID |
| funcid | Long | 功能号 |
| data_time | String | 数据时间 |
| data_value | Double | 能耗数据 |
设备能耗记录表dataobjectdatatime
| 字段名 | 类型 | 说明 |
| building | 建筑唯一标识 | |
| data_time | 数据时间 | |
| data_value | 能耗数据 | |
| objectSign | 设备唯一标识 |
分项能耗记录表dataenergydatatime
| 字段名 | 类型 | 说明 |
| building | String | 建筑唯一标识 |
| data_time | String | 数据时间 |
| data_value | Double | 能耗数据 |
| energyModelNodeSign | String | 能耗模型树节点标识 |
| energyModelSign | String | 能耗模型标识 |
计算任务表ci_instance
| 字段 | 类型 | 说明 |
| object_sign | String | 1101050001,1101050001-001 |
| instance_name | String | fjd_0_Acc_EnumV:计算分精度servicedata:能耗计算EMS:调研中计算单元和分项能耗计算stat_Inst:数据统计计算 |
| flag_valid | Long | |
| compute_interval_seconds | 计算时间间隔(秒) |
计算任务输入信息表ci_instanceinput
| 字段 | 类型 | 说明 | 举例 |
| dao_key | String | {"building":"1101050001","meter":"1001","funcid":10101} | |
| dao_type | String | fjd_near | |
| data_class | String | near | |
| input_sign | String | meterdata_1001_10101 | |
| instance_name | String | servicedata | |
| object_sign | String | 1101050001 | |
| source_instance_name | String | fjd | |
| source_object_sign | String | 1101050001 | |
| source_output_sign | String | 1001_10101 | |
| time_period | String | 15min |
计算任务输出信息表ci_instanceoutput
| 字段 | 类型 | 说明 | 举例 |
| custom_function_name | String | ||
| custom_paramsMap | String | ||
| dao_key | String | {"building":"1101050001","meter":"1001","funcid":10101} | |
| dao_type | String | servicedata | |
| data_class | String | consumption | |
| expression | String | 计算公式 | (meterdata_1001_10101'+1meterdata_1001_10101)*1.0 |
| instance_name | String | 实例名称 | servicedata |
| mode | String | expression | |
| need_all_var_data | Boolean | True | |
| object_sign | String | 建筑唯一标识 | 1101050001 |
| ouput_sign | String | servicedata_1001_10101 | |
| time_begin | String | 19700101000000 | |
| time_end | String | 19700102000000 | |
| time_period | String | 计算数据密度 | 15min |
| time_period_intialized | Boolean | True |
计算日志表ce_computelog
| 字段 | 类型 | 说明 | 举例 |
| compute_round | Long | 所计算的当前轮数 | 2110 |
| compute_time_from | String | 计算开始时间 | 20180707021500 |
| compute_time_to | String | 计算结束时间 | 20180707023000 |
| instance_name | String | 计算任务类型名称 | servicedata |
| is_finished | Long | 是否计算结束1 是 | 1 |
| object_sign | String | 项目表示 | 3101130001 |
计算日志输入信息表ce_computeinputlog
| 字段 | 类型 | 说明 | 举例 |
| compute_round | Long | 计算轮次 | 27 |
| compute_rounds | String | 13,101 | |
| instance_name | String | 计算实例名称 | servicedata |
| object_sign | String | 建筑唯一标识 | 1302020001 |
| source_instance_name | String | fjd_1 | |
| source_object_sign | String | 1302020001 |
计算日志输入信息详细表ce_computeinputdetail
| 字段 | 类型 | 说明 | 举例 |
| compute_round | Long | 1 | |
| input_sign | String | meterdata_1001_0 | |
| instance_name | String | servicedata | |
| object_sign | String | 1302020001 | |
| valid_time_from | String | 20160101000000 | |
| valid_time_to | String | 20160108000000 |
计算日志输出信息详细表ce_computeoutputdetail
| 字段 | 类型 | 说明 | 举例 |
| compute_round | Long | 1 | |
| instance_name | String | servicedata | |
| object_sign | String | 1302020001 | |
| output_sign | String | servicedata_1001_10101 | |
| valid_time_from | String | 20151231234500 | |
| valid_time_to | String | 20160108000000 |